The Interview That Humbled a Senior Engineer
Picture a senior engineer with five years of backend experience. They’ve built microservices at scale, debugged distributed systems at 3 AM, and worked through half of Designing Data-Intensive Applications. Then they walk into a senior engineering interview at a top-tier company.
The interviewer says: “Design a URL shortener.”
They know exactly how TinyURL works. They’ve read about it. But within 90 seconds, they’re drawing boxes on the whiteboard with no clear direction — jumping between database schemas and hashing strategies, talking faster than they’re thinking. Forty minutes later, they walk out knowing they failed. Not because they lacked knowledge, but because they had no framework for applying it under pressure.
This happens more often than you’d think. And it’s exactly what this system design interview guide is designed to prevent.
If you’re a mid-to-senior software engineer looking for a complete system design interview guide, this is it. Whether you’re targeting FAANG, high-growth startups, or any company that takes architecture seriously — this guide gives you the exact frameworks, real examples, and structured thinking models you need to walk in with confidence.
One truth to anchor everything that follows: system design interviews are judged more on your thinking process and trade-off awareness than on arriving at a “correct” answer. There is no single right design. There are only better and worse ways to reason about one.
Table of Contents
How System Design Interviews Actually Work in 2026
What Interviewers Are Actually Evaluating?
The evaluation criteria in 2026 haven’t changed dramatically, but the bar has risen. Interviewers at top-tier companies are looking for four things:
- Structured clarity under ambiguity: Can you take an open-ended prompt and break it into manageable pieces without hand-holding? The ability to impose structure on chaos is a signal of senior engineering thinking.
- Trade-off awareness: Every design decision has costs. Choosing SQL over NoSQL, push over pull, sync over async — interviewers want to hear you articulate why you’re making a choice and what you’re giving up in doing so.
- Scalability instinct: You don’t need to get the math precisely right, but you need to show you understand how the system behaves at 10x, 100x, and 1000x the initial load.
- Communication loops: This one is underrated. Strong candidates don’t monologue — they check in. “Does this direction make sense before I go deeper?” signals collaborative engineering, which is exactly what interviewers want to see on their team.
The Standard Interview Structure
A typical 45–60 minute system design interview in 2026 follows this arc:
PHASE
TIME
FOCUS
Require-ments
0–5 min
Functional + non-functional scope
Estimation
5–10 min
Scale, throughput, storage
High-level design
10–25 min
Major components, data flow
Deep dive
25–40 min
1–2 critical components in depth
Trade-offs
40–50 min
Bottlenecks, alternatives, failure modes
Weak vs. Strong Candidate
- Weak Candidate
“I’ll use a relational database, then add a cache layer, then a CDN…” (diving into solutions without establishing scope)
- Strong Candidate
“Before I start — are we optimizing for read-heavy or write-heavy traffic? And are we building this globally or for a single region? That changes the architecture significantly.”
The first two minutes set the tone for everything. Use them to ask two or three targeted clarifying questions, not to draw your first diagram.
The Winning Framework: A Step-by-Step Thinking Model
A repeatable framework is what separates candidates who perform consistently from those who get lucky. Every solid system design interview guide recommends one thing above all else: have a process before you have a solution. When you’re under pressure, your brain needs rails to run on. Here’s the framework that works:
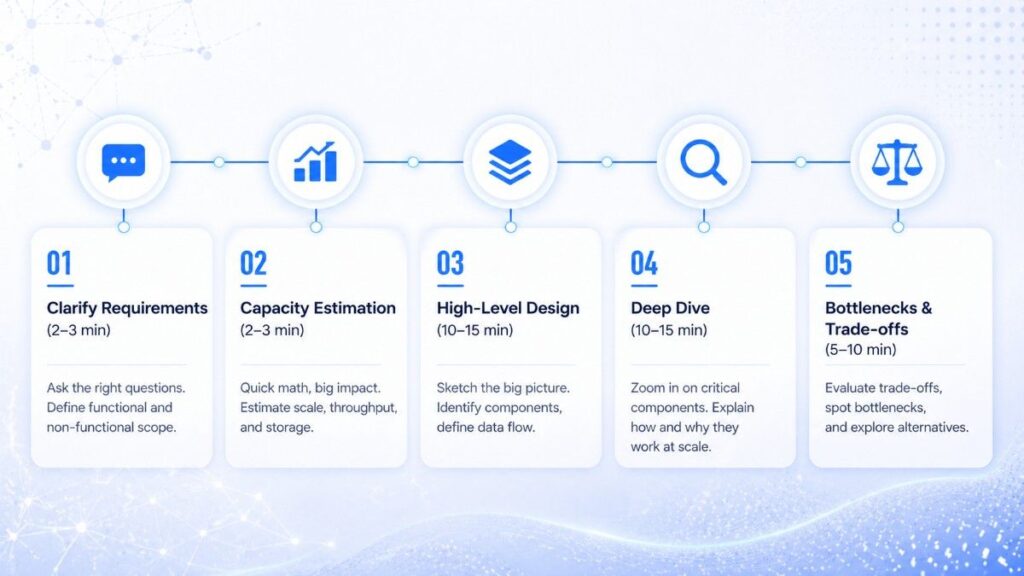
Step 1: Clarify Requirements (2–3 minutes)
Always start here. Ask about functional requirements first (“What does this system need to do?”) and then non-functional requirements (“What are our constraints around latency, availability, and consistency?”).
Useful questions to keep in your toolkit: How many daily active users? Is this read-heavy or write-heavy? Do we need global distribution? What’s the expected data retention period?
Don’t ask everything — ask the three questions whose answers would most change your design.
Step 2: Capacity Estimation (2–3 minutes)
Rough numbers, done quickly. Interviewers aren’t checking your arithmetic — they’re checking your intuition about scale. A few good estimates: “If we have 100M users and 1% post per day, that’s 1M writes/day, roughly 12 writes/second at peak with a 2x multiplier.” That’s enough.
Estimate storage separately from throughput. They drive different architectural decisions.
Step 3: High-Level Design (10–15 minutes)
Draw the boxes: clients, load balancers, application servers, databases, caches, message queues. Define the critical data flows with arrows. Identify the components you’ll need to go deep on.
Don’t optimize yet. This is your napkin sketch. Get alignment with the interviewer before committing to specifics.
Step 4: Deep Dive (10–15 minutes)
Pick the one or two components that are most interesting or challenging and go deep. This is where strong candidates separate themselves. An average candidate will describe what a component does. A strong candidate will explain why it’s designed this way, what breaks at scale, and how they’d handle it.
Step 5: Bottlenecks and Trade-offs (5–10 minutes)
End every design discussion with explicit trade-offs. “I chose eventual consistency here because it allows us to scale writes horizontally — if we needed strong consistency, I’d look at a different approach that would add latency but guarantee accuracy.” This is the language of senior engineering.
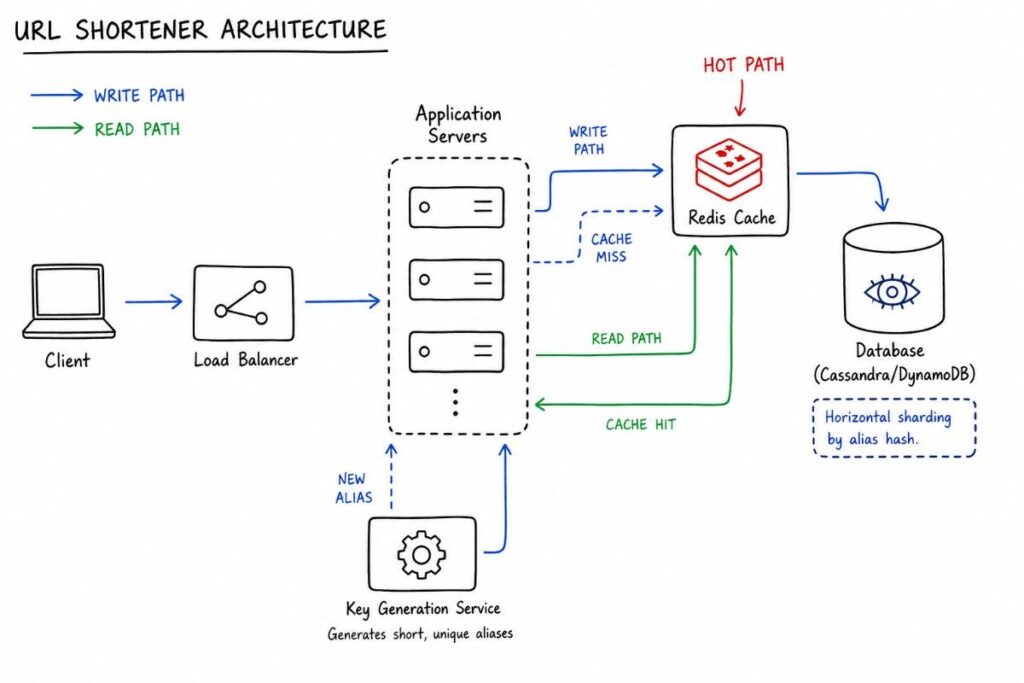
Example: Designing a URL Shortener (TinyURL)
This is the most commonly assigned warm-up problem. It’s deceptively simple — the interesting challenges live in the details.
Requirements:
- Functional: Given a long URL, return a short alias. Given a short alias, redirect to the original URL. Optionally: analytics (click counts, referrers).
- Non-functional: High availability, low read latency (redirects should be fast), eventual consistency is acceptable.
- Scale assumption: 100M URLs shortened per day, 10:1 read-to-write ratio.
API Design:
POST /shorten → { longUrl } → { shortUrl, alias }
GET /{alias} → 301/302 redirect to longUrl
Use 302 (temporary redirect) if you want click analytics, 301 (permanent redirect) if you want to reduce server load. That’s a real trade-off worth mentioning.
Hashing Strategy
Approach
Trade-off
Best for
MD5 truncated
Collision risk at scale
Low traffic, simple setups
Base62 (auto-increment ID)Low
Sequential IDs are guessable
Internal tools
Key Generation Service (KGS)
More infrastructure
Production at scale
Database and Scaling Reads
With 100M entries/day and 5-year retention, you’re looking at ~180 billion records. This argues strongly for NoSQL (Cassandra / DynamoDB) — the access pattern is simple key-value lookups and you need horizontal scalability.
A Redis cache with LRU eviction handles the hot-key problem — the top 20% of aliases likely account for 80% of redirects.
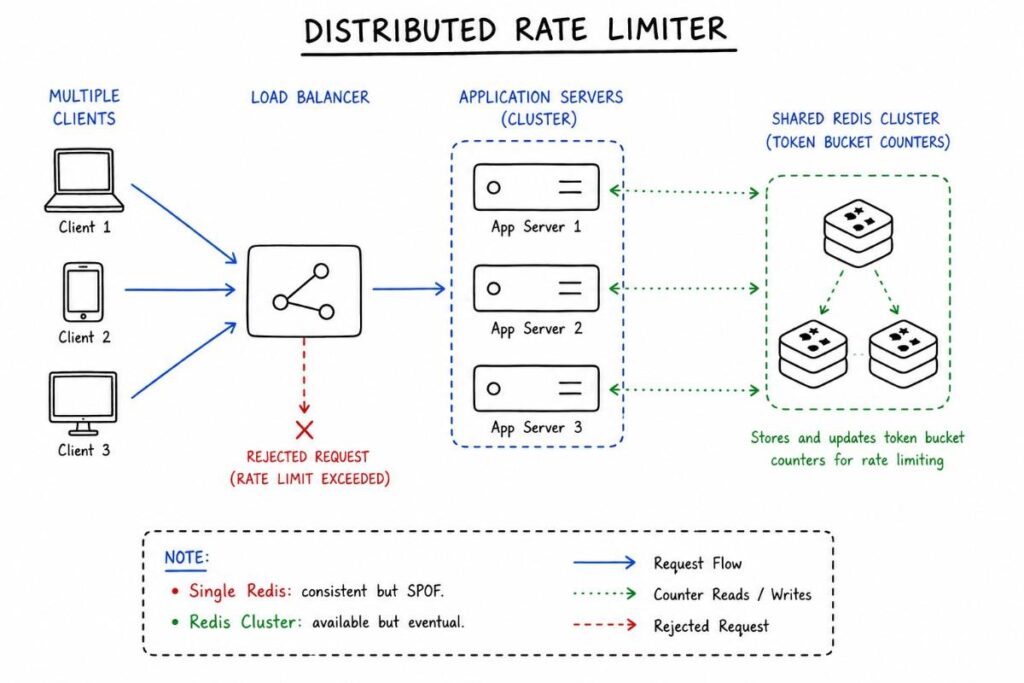
Example: Designing a Rate Limiter
Rate limiting is one of the most practical and frequently assigned problems in a system design interview. Every production API needs it.
The Core Problem
You’re protecting an API service from abuse — whether from a single bad actor flooding requests or a legitimate client with runaway retry logic. The rate limiter sits in front of your service and enforces policies like “100 requests per minute per user.”
Algorithms Compared
Algorithm
Burst Handling
Complexity
Used By
Token Bucket
✅ Allows bursts
Low
AWS, Stripe
Leaky Bucket
❌ Smooths bursts
Low
Traffic shaping
Fixed Window
Boundary exploit
Very low
Simple APIs
Sliding Window
✅ Accurate
Medium
Production APIs
The Distributed Challenge
A single-server rate limiter is trivial. The interesting problem is: what happens when you have 50 application servers?
If each server maintains its own counter in local memory, a client that round-robins across servers can exceed the global rate limit by a factor of 50. You need a shared, low-latency counter store.
Redis is the canonical answer here. INCR and EXPIRE in Redis are atomic operations that allow you to maintain a per-user counter with millisecond latency.
INCR user:{userId}:window:{timestamp}
EXPIRE user:{userId}:window:{timestamp} {window_seconds}
Consistency vs. Availability Trade-off
Here’s where strong candidates shine. Redis with a single master gives you consistency but introduces a single point of failure. Redis Cluster gives you availability but introduces potential counter divergence across shards during network partitions.
For most rate-limiting use cases, being slightly off on the count (allowing 105 requests instead of 100 in a rare edge case) is acceptable. You’d choose availability over strict consistency. If you’re rate-limiting financial transactions, that calculus changes.
Saying this explicitly in an interview signals production-grade thinking.
- Single Redis Master
Consistent counters, but single point of failure. Acceptable for non-critical APIs.
- Redis Cluster
Highly available, but possible counter divergence during partitions. For most use cases, being off by a few requests is acceptable — choose availability.
Frequently Asked Questions
What is a system design interview?
A system design interview is an open-ended technical discussion where candidates design large-scale distributed systems — like a messaging platform, search engine, or payment processor — to demonstrate architectural thinking, scalability awareness, and trade-off reasoning.
How do you structure a system design answer?
Use the five-step framework: clarify requirements → estimate capacity → sketch a high-level design → deep dive into critical components → discuss trade-offs and bottlenecks. Spend roughly 2–5 minutes on each stage, checking in with the interviewer as you go.
What are common mistakes in system design interviews?
Starting to design before clarifying requirements, covering too many components superficially, treating the design as final rather than iterative, and failing to acknowledge failure scenarios or consistency trade-offs.
How much depth is expected in a system design interview?
At the senior level, interviewers expect you to go deep on one or two components — not cover everything. Depth over breadth signals seniority. Be ready to discuss database indexing strategies, cache invalidation policies, or consensus algorithms at a production-grade level.
How do I prepare for system design interviews in 2026?
The most effective system design interview guide for 2026 focuses on three things: a repeatable framework, canonical examples, and deliberate trade-off practice. Practice designing three to five canonical systems using a consistent framework. Platforms like Gururo offer mock system design interviews that simulate real interview conditions — timed practice with structured feedback is the fastest path to improvement.
Final Thoughts
Here’s what separates engineers who consistently pass system design interviews from those who don’t: it’s not deeper knowledge — it’s a repeatable process.
The framework in this system design interview guide isn’t magic. It’s a cognitive scaffold that lets you apply what you already know under pressure. Requirements before architecture. Estimation before optimization. Depth over breadth. Trade-offs, always.
The strongest candidates don’t walk in knowing the “right” answer. They walk in knowing how to reason well about any answer.
Bookmark this system design interview guide 2026 and return to it after each mock session to track how your thinking evolves.
- Bonus Challenge
Design Instagram’s Feed System in 10 Minutes
Apply the framework right now — set a timer and work through these steps:
- What are the core functional requirements? (posting, following, feed generation)
- What’s the scale? Estimate DAU, posts per day, feed reads per second
- What’s your high-level design? Which components do you need?
- What’s the hardest part? Fan-out on write vs. fan-out on read — this is the crux
- What trade-off would you make, and why?
Drop your approach in the comments. There’s no better way to test your understanding than writing it out.