





The Netflix recommendation algorithm is responsible for nearly everything you watch on the platform—often before you even realize it.

Why It Feels Like It Knows You Better Than You Do?
The Netflix recommendation algorithm is responsible for nearly everything you watch on the platform—often before you even realize it. This frictionless experience is not a coincidence; it is the output of the recommendation algorithm, a system engineered to predict not just what you might like, but what you are most likely to consume right now.
Unlike traditional academic recommendation algorithms that optimize purely for prediction accuracy (minimizing error), production-scale systems at Netflix optimize for engagement, retention, and decision efficiency. This article synthesizes insights from industry research to dissect the architecture of this engine.
We will explore four foundational pillars:
System
Architecture
Collaborative
Filtering
Matrix
Factorization
Learning
to Rank
Table of Contents
System Architecture: The Real-Time Decision Pipeline
It is a common misconception that the Netflix recommendation algorithm is a single, monolithic model. In reality, as detailed in numerous architectural breakdowns on GitHub and the Netflix Tech Blog, it is a multi-tiered, cascading pipeline designed to progressively filter and refine millions of data points into a single, personalized user interface.
At its core, the system must rapidly transition from a universe of possibilities to a highly curated selection by answering three sequential questions:
Candidate Generation: Out of thousands of titles, which subset (usually a few hundred) is relevant to this user based on broad historical data?
Filtering & Scoring: How relevant is each candidate item to the user’s current context (time of day, device, recent watch history)?
UI Personalization (Ranking): How should these items be visually presented—which rows, what order, and with which thumbnail?
For Example: Consider the “Contextual Bandit” approach. A user might consistently watch dense crime thrillers late at night on a smart TV, but prefer 20-minute sitcoms during a lunch break on a mobile device. The candidate generation phase pulls both genres, but the scoring phase applies real-time contextual weights to push the sitcoms to the top during lunch hours.
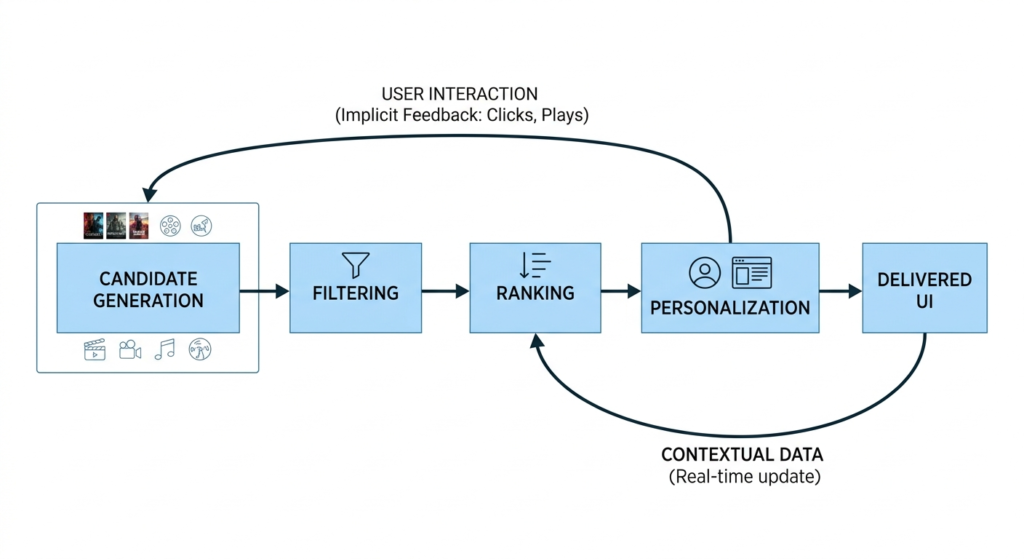
Data Signals: The Fuel of the Pipeline
The effectiveness of this pipeline relies heavily on the shift from explicit feedback (e.g., star ratings) to implicit feedback. As noted across social media, what users say they like often contradicts what they actually watch.
Implicit signals include:
- Watch time: The most heavily weighted indicator of engagement.
- Interaction pacing: Replays, pauses, and abandonment rates.
- Contextual metadata: Time of day, day of the week, and device type.
Collaborative Filtering & The Power of Implicit Collectivism
Before a system can rank content, it must understand affinity. The foundational layer of Netflix’s candidate generation is Collaborative Filtering (CF). Rather than relying on natural language processing to understand what a movie is “about” (Content-Based Filtering), CF leverages the collective behavioral patterns of millions of users.
The Mechanics of Item-to-Item CF
In the early days of e-commerce and streaming, models relied on User-Based CF (finding users similar to you). Instead of matching a user to similar users, the algorithm calculates the similarity between items based on how often they are co-consumed.
Let’s use an example:
User A watches Narcos, Breaking Bad, and Mindhunter.
User B watches Breaking Bad and Mindhunter.
Even if the system has no metadata telling it that these are “crime dramas,” the algorithmic logic identifies a mathematical neighborhood.
Because the items share a high degree of overlap in their consumer base, the system computes a strong probability that User B will engage with Narcos.
Matrix Factorization: Mapping the Latent Space
The raw User-Item Interaction Matrix is massively sparse; a typical user might only watch 0.1% of the catalog. Naive similarity calculations break down at this level of sparsity. The breakthrough solution—which famously won the $1M Netflix Prize—was Matrix Factorization, specifically techniques utilizing Singular Value Decomposition (SVD).
As detailed by Yehuda Koren in his foundational paper Matrix Factorization Techniques for Recommender Systems, this method reduces the dimensionality of the sparse matrix into dense vectors. The goal is to discover a “latent space” where both users and items can be plotted.
Mathematically, if R is the sparse user-item interaction matrix, we want to decompose it into two lower-dimensional matrices, P (representing user features) and Q (representing item features), such that their dot product approximates the original matrix:
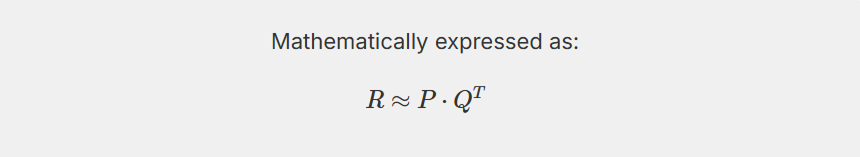
The model doesn’t know what these features are in human language. It doesn’t label a dimension as “Action” or “Thriller”. Instead, it might mathematically isolate a dimension that represents “Pacing” (from slow-burn documentaries to frenetic action) or “Emotional Tone” (from dark/cynical to light/uplifting).
If a user’s vector Pu closely aligns with an item’s vector qi in this multi-dimensional space, the dot product of the two vectors will be high, resulting in a strong recommendation score. Two shows might share absolutely zero tags or actors, but if users consume them in identical patterns, they will be clustered tightly together in the latent space.
Learning to Rank (LTR): The Final Optimization Layer
Generating highly accurate, latent-space-backed candidates is only half the battle. Presenting a user with a list of 50 highly relevant, identical crime thrillers leads to rapid content fatigue. The final step is Learning to Rank (LTR), where the system optimizes a multi-objective function.
Balancing Relevance, Diversity, and Novelty Modern recommender systems do not sort purely by the highest predicted score. Instead, they frame UI generation as a complex optimization problem. The ranking layer must balance:
Relevance: The baseline likelihood of a user watching an item.
Diversity: Ensuring a single genre or format doesn’t monopolize the screen.
Novelty/Serendipity: Introducing unexpected content to map new areas of the user’s latent preference vector (a concept rooted in the Exploration vs. Exploitation dilemma in reinforcement learning).
Netflix takes this a step further by personalizing the artwork itself. If the LTR model determines that a user’s latent vector heavily favors “comedy,” the thumbnail for a movie like Good Will Hunting might feature Robin Williams. If the vector favors “romance,” the thumbnail might feature Matt Damon and Minnie Driver. This is often powered by contextual bandits that learn which visual variations drive the highest click-through rates for specific user clusters.
Ultimately, offline metrics like Root Mean Square Error (RMSE) are useful for training, but production models are evaluated through rigorous A/B testing on live traffic. If a model improves theoretical accuracy but decreases session duration or retention, it is rolled back.
Conclusion
The Netflix recommendation algorithm represents a masterclass in applied machine learning. It is not defined by a single elegant equation, but by the robust orchestration of collaborative filtering for behavioral insights, matrix factorization for understanding the hidden architecture of human preference, and complex ranking systems that optimize for real-world engagement over theoretical perfection.
For data scientists and machine learning engineers, the evolution of this system proves a vital industry truth: algorithms only succeed when they are deeply empathetic to human behavior. Data quality, implicit signals, and an understanding of the user context will always out-scale raw model complexity. For practitioners building platforms (from e-commerce to educational ecosystems like Gururo), mastering these underlying mechanics is the critical first step in turning data into engaging, personalized experiences.
FAQs: Netflix Recommendation Algorithm
What is the Netflix recommendation algorithm?
The Netflix recommendation algorithm is a machine learning system that predicts and ranks content based on user behavior, preferences, and real-time context. Instead of relying on explicit ratings, it uses implicit signals like watch time, interaction patterns, and device usage to personalize what each user sees.
How does collaborative filtering work in the Netflix recommendation algorithm?
Collaborative filtering in the Netflix recommendation algorithm identifies patterns across users by analyzing shared viewing behavior. For example, if users who watched Breaking Bad also watched Narcos, the system recommends Narcos to similar users—even without understanding the content itself.
Why does Netflix use matrix factorization in its recommendation system?
Matrix factorization helps the Netflix recommendation algorithm handle sparse data by mapping users and content into a latent feature space. This allows the system to uncover hidden preferences—such as tone or pacing—enabling accurate recommendations even when direct interactions are limited.
How does Netflix personalize recommendations in real time?
The Netflix recommendation algorithm adapts recommendations using real-time contextual signals like time of day, device type, and recent activity. For example, it may prioritize short, light content during daytime viewing and longer, immersive shows at night.
What role does ranking play in the Netflix recommendation algorithm?
Ranking is the final and most critical step in the Netflix recommendation algorithm. It determines how content is displayed by balancing relevance, diversity, and novelty. This ensures users see not just accurate recommendations, but a varied and engaging selection that prevents content fatigue.