






Hidden Factors That Control TikTok's For You Page in 2026
Most explanations of the FYP stop at “watch time matters.” That’s like explaining a jet engine by saying “fuel burns.” Here’s what’s actually happening inside TikTok’s recommendation stack — and why ML engineers should care deeply about it.
Table of Contents
In 2021, a leaked internal TikTok document titled “TikTok Algo 101” gave the world its first real glimpse at the machinery behind the For You Page. It showed something surprising: TikTok wasn’t optimizing for the social graph — the network of who you follow — the way every other major platform had been doing for a decade. It was doing something architecturally different, and more powerful.
The document revealed a system built around predicting the probability of specific user actions — what TikTok calls pCVR (probability of completion), pLike, pShare, pComment — and combining those predictions into a weighted value score. The platform then optimizes for that score using a reinforcement learning loop that updates based on every micro-interaction a user makes.
Understanding this system matters beyond TikTok itself. The FYP’s architecture has become a reference design that YouTube Shorts, Instagram Reels, and Snapchat Spotlight have all adopted in some form. For ML engineers and technical product managers, fluency with this system is increasingly table stakes.
This deep dive will walk you through the algorithm’s actual mechanics — not the simplified version you’ve heard before.
1B+
Monthly active users
95m
Avg daily minutes per user
<1s
Cold-start latency target
34%
Watch time from suggested
Why the FYP Is the Most Consequential Algorithm in Consumer Tech
Every major platform has a recommendation algorithm. What makes TikTok’s different is its cold-start performance. When you open a fresh TikTok account and scroll for 30 minutes without following a single person, the For You Page is already serving you personalized content. By 45 minutes in, it has built a working model of your micro-preferences.
No other platform at scale does this. Instagram’s Reels rely heavily on your existing social graph to bootstrap recommendations. YouTube needs a watch history. Spotify needs listening patterns. TikTok infers preference from zero prior data using only in-session behavior signals — essentially, it watches how you watch.
Key Insight
This cold-start capability is the product’s strategic moat. It lowers the barrier to getting value from the app to near zero. Any new user who scrolls for a few minutes is immediately rewarded — which explains TikTok’s unusually high D1 retention rates compared to other social media apps.
Every major platform has a recommendation algorithm. What makes TikTok’s different is its cold-start performance. When you open a fresh TikTok account and scroll for 30 minutes without following a single person, the For You Page is already serving you personalized content. By 45 minutes in, it has built a working model of your micro-preferences.
No other platform at scale does this. Instagram’s Reels rely heavily on your existing social graph to bootstrap recommendations. YouTube needs a watch history. Spotify needs listening patterns. TikTok infers preference from zero prior data using only in-session behavior signals — essentially, it watches how you watch.
The Signal Architecture: What the Model Actually Reads
Before we can talk about what the FYP optimizes, we need to understand what it reads. TikTok’s ranking model ingests signals from three distinct categories, each contributing differently to the final value score.
User behavior signals
These are the highest-weight inputs and the source of TikTok’s cold-start magic. The platform captures an extremely granular behavioral log for every session: exact watch duration, replays (including partial replays), swipe-away timestamp, profile visits from video, hashtag interactions, and the presence or absence of a “search after video” action — meaning the user watched something and then searched for more like it.
The most important of these is watch-time ratio, not raw watch-time. A 60-second video watched for 55 seconds is a stronger positive signal than a 10-second clip watched to completion. TikTok normalizes completion rate against video length, which is why gaming this metric requires understanding the denominator.
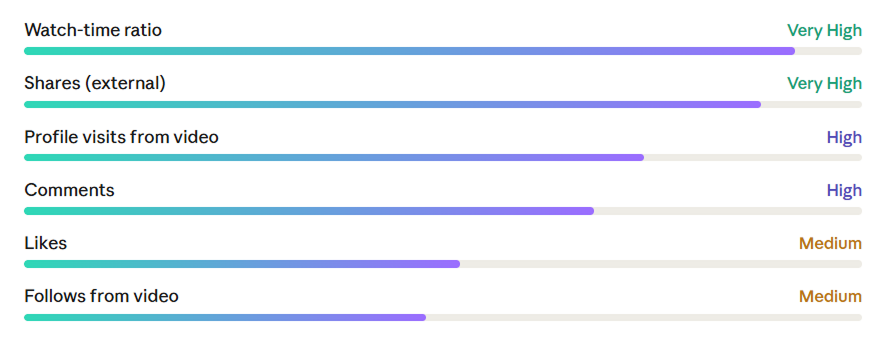
Note that likes are medium-weight, not high. This surprises most people. TikTok’s research found that likes are a noisy proxy for genuine engagement — users often double-tap as a passing gesture. External shares are a far more reliable signal of deep interest because they require intent and carry social cost.
Content signals
The platform analyzes video content through several parallel pipelines: a computer vision model that classifies scene, objects, and visual style; an audio model that classifies music genre, speech content, and audio-visual alignment; and a natural language processing pipeline that ingests caption text, hashtags, and user comments at near-real-time latency.
Together these build a content embedding — a high-dimensional vector that represents what a video is “about” in a way that enables similarity matching during the retrieval stage.
Device and environmental context signals
This is the category most creators and even many ML practitioners undercount. TikTok ingests: device type and OS version, current time of day and day of week, network connectivity type (Wi-Fi vs cellular), battery level, and geographic region at the city level. These aren’t minor adjustments — time-of-day and battery level in particular have meaningful effects on both what content is served and how long sessions last.
ML Engineering Note
The environmental context features address a classic problem in session-based recommendation: distribution shift between training and serving. A model trained on Monday morning data performs poorly on Friday night without context features that allow the model to condition its predictions on time. TikTok solves this with explicit temporal features, not just embeddings.
Two-Stage Retrieval-Ranking: Where the Real Work Happens
The FYP doesn’t run one monolithic model over all available video content to produce your feed. That would be computationally impossible at scale. Instead, like all major production recommendation systems, TikTok operates a cascade of models with decreasing latency requirements and increasing model complexity at each stage.
Stage 1 → 2: Coarse retrieval
The retrieval model doesn’t score videos — it retrieves candidates. Using a lightweight two-tower neural network (one tower for user representation, one for video representation), TikTok computes approximate nearest neighbors between your current user embedding and the full video index using vector similarity search. This produces a shortlist of roughly 10,000 candidates in milliseconds.
The key design choice here is that the user tower is updated in near-real time within a session. As you engage with content, your user embedding shifts. The retrieval model sees a slightly different version of you after every few interactions. This is what drives the FYP’s ability to “lock in” on your current mood or interest state — if you watch three cooking videos in a row, your embedding moves toward the cooking cluster, and the retrieval model starts pulling more cooking candidates even before the ranking stage makes any decisions.
Stage 2 → 3: Fine-grained ranking
The ranking model is where most of the ML sophistication lives. TikTok uses a multi-task learning architecture — a single model with a shared lower network and task-specific heads that simultaneously predict pCVR (watch completion), pLike, pShare, pComment, and pFollow. Each prediction gets a weight, and the weighted sum produces a final value score.
The formula is roughly:
Value Score Formula (approximate)
Value = w₁·pCVR + w₂·pShare + w₃·pComment + w₄·pLike + w₅·pFollow
Where the weights are not disclosed and are themselves learned parameters that change over time based on business objectives. TikTok can shift user behavior at scale by adjusting these weights — amplifying comment-driving content or share-driving content depending on strategic goals.
Stage 3 → 4: Re-ranking and filtering
The final stage applies rules that the pure ML models don’t capture: safety classifiers that catch harmful content, deduplication logic that prevents showing the same creator or sound twice in close succession, and a diversity constraint that ensures the feed doesn’t collapse into one topic. This last step is more important than it appears — without it, a ranking model purely optimizing the value score would create hyper-specialized feeds that are engaging in the short term but cause session fatigue and churn over days.
The Interest Graph vs. The Social Graph: TikTok's Core Bet
The single most important architectural decision in TikTok’s recommendation system is one that gets surprisingly little analytical attention: the choice to build around an interest graph rather than a social graph.
Facebook’s news feed, Instagram’s core feed, and Twitter’s timeline all started from the same premise: the most useful signal about what content you want is who you’re connected to. The social graph is the model. Your feed is a filtered view of your network’s activity.
“TikTok’s bet was that what you’re interested in is a far richer signal than who you know — and that machine learning could infer interest without requiring social connections to bootstrap it.”
This distinction has profound implications for the cold-start problem. A new user on Facebook has no social graph — they see a nearly empty feed until they follow enough people. A new user on TikTok has no social graph either, but that doesn’t matter. The interest graph is inferred entirely from behavior, not from explicit social connections.
How the interest graph is constructed
TikTok builds a multi-layered interest representation for each user:
-
1. Explicit interest tags
— derived from hashtags the user has interacted with, topics they’ve searched, and sounds they’ve used if they’re a creator.
-
2. Implicit behavioral interests
— inferred from the content embeddings of videos where the user showed strong engagement signals (high watch time, repeat views, profile visits).
-
3. Temporal interest decay
— interests are time-weighted. Something you were obsessed with two months ago has less influence on today’s recommendations than something you engaged with yesterday. This is implemented via exponential decay applied to historical interaction weights.
-
4. Session-level interest state
— a transient representation that captures what you seem to want right now in this session, separate from your historical profile. This is what drives the “mood detection” behavior people notice.
Practical Implication for Creators
The session-level interest state is why TikTok can surface your video to someone who has never engaged with your niche before — if a user has been watching adjacent content in the same session, their transient embedding moves toward your topic. Distribution doesn’t only come from your existing audience; it comes from interest-graph neighbors of your topic, including people who don’t yet know they’re interested in it.
| Dimension | Social Graph Model (Meta/X) | Interest Graph Model (TikTok) |
|---|---|---|
| Cold-start performance | Poor — needs social connections | Strong — infers from behavior |
| Discovery of new creators | Limited — follows drive reach | High — interest matching enables viral reach |
| Filter bubble risk | Medium | High — requires diversity injection |
| Creator leverage | Low — follower count dominates | High — content quality can overcome small audience |
| Privacy sensitivity | Moderate | High — requires deep behavioral logging |
Reinforcement Learning Loop: How the FYP Optimizes Over Time
The ranking model described above is a supervised learning system — it predicts action probabilities based on a snapshot of user and content features. But TikTok’s broader recommendation system also incorporates a reinforcement learning (RL) component that operates at a longer time horizon than a single session.
Here’s the problem that RL solves: a purely greedy ranker will serve whatever has the highest immediate value score. Over time, this creates a feedback loop where the system serves more of what you’ve already shown interest in, which narrows your profile, which causes the system to serve an even narrower range — a problem known in the literature as filter bubble amplification.
TikTok’s RL loop treats the recommendation problem as a Markov Decision Process (MDP). The state is the user’s current profile and session context. The action is the next video to serve. The reward is a combination of immediate engagement signals (the value score) and long-horizon retention signals — whether the user came back the next day, how long their next session was, whether they churned in the following week.
Key Technical Challenge
Reward sparsity is the core difficulty in RL-based recommendation. Immediate signals (watch time, likes) are dense and available per-video. Long-horizon signals (next-day retention) are sparse and delayed. TikTok’s system uses reward shaping — augmenting the sparse long-horizon signal with intermediate proxies — to make the RL training tractable.
Exploration vs. exploitation in the FYP
Any RL-based recommendation system must balance exploitation (serving content it knows you’ll like) with exploration (trying content outside your known interests to potentially expand your profile and improve long-term satisfaction). TikTok injects exploration through two mechanisms:
First, a small percentage of each feed — reportedly around 5–10% — is reserved for “exploration slots” where the ranker explicitly serves content from interest clusters adjacent to but not identical with your current profile. These videos are treated as experiments; their engagement data feeds back into the RL training pipeline.
Second, the diversity constraint in Stage 4 serves a dual function — it prevents feed monotony (a user experience reason) and enforces exploration across topic clusters (a system learning reason). Forcing topical variety means the system continuously gathers data on how users respond to content slightly outside their comfort zone.
The Hidden Factors Most Creators and Engineers Miss
Most public writing about the FYP algorithm focuses on the features and signals that are intuitive: post at the right time, use trending sounds, write good captions. These things matter, but they sit at the visible surface of a much more interesting system. Here are the factors that rarely get discussed.
The “not interested” signal is asymmetric
When a user taps “Not interested” on a video, or swipes away very quickly (under 2 seconds on a 30+ second video), TikTok doesn’t just decrease the score for that creator. The platform uses this negative signal to update the user’s content avoidance profile — a representation of topics, formats, and even visual styles that generate negative engagement. This profile is weighted asymmetrically: a single strong negative signal (explicit “Not interested” tap) can suppress an interest cluster that took multiple positive engagements to build.
Audio-visual mismatch is a distribution penalty
TikTok’s content analysis models score the semantic alignment between audio and visual content. A video where the music doesn’t match the visual pacing, or where the caption topic doesn’t match the visual scene, scores lower on a quality coherence metric that influences distribution — independent of whether it gets high initial engagement. This is one reason high-production-value content on TikTok still needs to respect format-native conventions.
Follower count is input, not output
One of the most misunderstood aspects of TikTok’s ranking model is that follower count is treated as a feature input, not as a distribution multiplier. An account with 10 million followers doesn’t get a 10x distribution bonus compared to an account with 1 million followers. Follower count affects the prior probability of engagement (a signal the model uses to weight initial distribution), but the actual distribution is rapidly updated based on real-time video performance. A new creator with a genuinely high-performing video can achieve the same reach as a major account within hours — which is architecturally intentional and is why TikTok’s creator ecosystem has more mobility than Instagram’s.
The “cohort neighbor” effect
TikTok uses collaborative filtering as part of its retrieval stage, which means your recommendations are influenced not only by your own behavior but by the behavior of users with similar behavioral profiles — your “cohort neighbors.” If 500 users with a profile similar to yours all watched and rewatched a video that you haven’t seen yet, that video will score higher in your retrieval stage even without any direct evidence that you’d like it. This is the mechanism behind the “how did TikTok know I’d like this” experience — the answer is that someone statistically similar to you already told it.
Frequently Asked Questions
Does the TikTok For You Page algorithm really work without any followers?
Yes, by design. TikTok’s interest graph model is built to function in the absence of social connections. The cold-start problem is addressed through in-session behavioral inference — the system builds a working model of your preferences from watch patterns within a single session, before any social graph is established. This is one of TikTok’s core architectural differentiators compared to Instagram or Facebook.
What is the single most important signal for TikTok's recommendation algorithm?
Watch-time ratio — the percentage of a video that a user watches, normalized by video length — is consistently described as the highest-weight engagement signal. It outweighs likes, comments, and follows because it’s harder to fake and requires sustained attention. External shares (outside the app) are second, as they represent high-intent engagement with social cost attached.
Why does TikTok sometimes show content that seems completely unrelated to my interests?
This is the exploration component of the RL recommendation loop. TikTok deliberately inserts a small percentage of “exploration” content from interest clusters adjacent to your known preferences. The goal is dual: prevent filter bubble collapse, and gather data on latent interests that your existing profile doesn’t capture yet. If you engage with the “random” content, the system updates your profile; if you swipe away, it calibrates the boundary of your interest graph.
How does TikTok's algorithm affect career opportunities for ML engineers?
The FYP’s architecture — multi-task learning, two-stage retrieval-ranking, real-time embedding updates, RL-based long-horizon optimization — represents the current frontier of production recommendation systems. Engineers who can demonstrate understanding of this architecture in depth are better positioned for roles at major platforms that run comparable systems: YouTube, Spotify, Airbnb, and others. System design interviews at these companies routinely probe understanding of retrieval-ranking pipelines, embedding freshness tradeoffs, and exploration-exploitation balance.
Is TikTok's For You Page algorithm different in 2026 than it was in earlier years?
The core architecture — interest graph, two-stage funnel, multi-task ranking — has remained stable. What has evolved significantly is the sophistication of the content understanding pipeline (better video and audio embeddings), the real-time latency of user embedding updates (now near-instantaneous within sessions), and the increased weight placed on long-horizon retention signals as TikTok’s RL infrastructure has matured. The business-objective weighting in the value score formula has also shifted to place more emphasis on comment engagement as TikTok has invested in community features.
What This Means — For Creators, Engineers, and the Industry
TikTok’s For You Page is not a black box that rewards virality through mysterious means. It is an extraordinarily well-engineered system with clear architectural logic. It prioritizes behavioral signals over social graph signals because behavioral signals are more informative and more democratically distributed. It uses a two-stage funnel because the tradeoff between retrieval speed and ranking precision is an engineering constraint, not a business choice. It incorporates reinforcement learning because greedy short-horizon optimization eventually destroys engagement diversity and churn — a problem that looks like engagement in the near term and like platform death in the long term.
For creators, understanding this architecture means knowing where the real leverage points are: not gaming vanity metrics, but engineering genuine early-session engagement from non-followers — because that’s the signal the retrieval model uses to expand distribution.
For ML engineers, it means having a production-grade reference architecture for interest-based recommendation that you can analyze at multiple levels of abstraction — which is exactly what system design interviewers at top tech companies are evaluating when they ask you to “design a recommendation system.”