






How does DoorDash know when your food will arrive?
You’re sitting on your couch at 7:02 PM. Your stomach is making sounds usually reserved for whale communication. You hit “Order.” The app looks back at you and whispers: “32 minutes.”
That number isn’t just a guess. It’s a prediction generated by a global-scale supercomputer calculating the trajectory of thousands of variables in milliseconds. DoorDash’s ETA Prediction System sits at the intersection of high-frequency data streams, geospatial intelligence, and models that must learn from their own mistakes in seconds.
This deep dive explores how DoorDash engineers its ETA systems, the architectural trade-offs between speed and accuracy, and why delivery logistics is arguably the “final boss” of real-time machine learning.
Table of Contents
Why ETA Prediction is One of the Hardest ML Problems?
At first glance, predicting an ETA looks like a standard regression task. You have a starting point (A), an ending point (B), and a distance. In a perfect vacuum, the formula would be simple physics.
However, the “last mile” of delivery is anything but a vacuum. Reality introduces high-entropy chaos, where tiny changes at the beginning of the chain result in massive delays at the end. Unlike a GPS predicting a highway drive, food delivery involves “The Last 100 Feet”—parking, elevators, and kitchen queues.
Kitchen Latency
A restaurant might have 50 orders in the queue or zero. A chef might drop a tray.
Dasher State
Experience matters. Local pros know shortcuts that GPS isn't aware of yet.
Vertical Travel
Delivering to the 30th floor of a downtown condo adds ~6 mins of "hidden" travel.
The "Black Box" of Kitchens
A restaurant’s status isn’t a static variable. A kitchen might have 50 orders in the queue or zero. A chef might drop a tray, or a merchant might simply forget to hit the “Order Ready” button on their tablet. Because the ML model cannot “see” inside the kitchen, it must rely on operational proxies—like historical prep times for that specific hour or the current number of active Dashers in the store’s vicinity—to guess the internal state of the merchant.
The Human Factor
Dashers are not autonomous drones; they are individuals with varying levels of experience.
Veterans: Might know which side-street avoids a long school-zone light or which apartment complexes have broken gates.
Newcomers: May struggle with finding parking in a dense downtown grid, adding “unseen” minutes to the handoff.
Geospatial Ephemerality
Traffic isn’t just “heavy” or “light.” It’s a living organism. A double-parked delivery truck on a one-way street or a sudden localized downpour can create a “traffic anomaly” that traditional GPS apps might not register for another 10 minutes. This creates geospatial decay, where the data used to make the prediction is already obsolete by the time the Dasher starts their engine.
The Secret Sauce: Feature Engineering
If the algorithm is the chef, the features are the ingredients. You can have the best chef in the world, but if the tomatoes are rotten, the salsa will be terrible. In DoorDash’s delivery time prediction ML, feature engineering is where the “magic” happens, turning raw GPS pings into meaningful predictions.
H3 Hexagons: The Geospatial Brain
DoorDash doesn’t see maps as a simple grid of streets. They use Uber’s H3 indexing system, which partitions the entire world into a grid of tiny, nested hexagons.
Why hexagons instead of squares?
Uniform Neighbor Distance: In a square grid, the distance from the center to a neighbor sharing an edge is different from one sharing a corner. In a hexagon, the distance to the center of all six neighbors is identical.
Mathematical Smoothing: This uniformity makes calculating traffic flow or Dasher supply across a city much more accurate. It prevents “edge effects” that could skew a prediction just because a Dasher crossed a line.
The Sky-High Challenge: Vertical Travel Time
In dense urban jungles like NYC, Chicago, or London, the “Last Mile” is often the “Last 100 Feet Up.” Standard GPS tells the model the Dasher has arrived at the building, but it doesn’t account for:
Waiting for a freight elevator.
Security check-ins at the front desk.
Walking down long hallways in massive complexes.
To solve this, DoorDash engineers include Point of Interest (POI) attributes as features. If the delivery address is a 40-story office building versus a single-story suburban bungalow, the model applies a “vertical latency” coefficient. This adjusts the ETA to account for the extra 5–10 minutes it takes to actually reach your door after the car has parked.
The Concept of "Feature Decay"
In logistics, features have a “shelf life.” The fact that a restaurant was busy two hours ago is almost irrelevant. The fact that they were busy five minutes ago is everything. DoorDash’s engineering team focuses on low-latency feature engineering, ensuring the model “forgets” old data and prioritizes the immediate heartbeat of the city.
By combining the mathematical elegance of H3 Hexagons with the granular reality of Vertical Latency, DoorDash moves beyond “guessing” and into the realm of high-fidelity simulation.
Why Gradient Boosting Still Wins?
While Deep Learning (Neural Networks) gets the headlines, DoorDash and many other logistics giants (like Uber and Lyft) lean heavily on Gradient Boosted Decision Trees (GBDT)—specifically frameworks like XGBoost and LightGBM.
Despite the rise of Large Language Models and complex neural architectures, tree-based models remain the “gold standard” for tabular logistics data.
DoorDash engineers have explicitly stated that while they experiment with Deep Learning for specific tasks, GBDTs like LightGBM were selected as the primary framework because they offer the best balance of training speed and prediction accuracy.
In an official deep-dive, DoorDash’s engineering team noted that while the accuracy between frameworks like XGBoost and LightGBM was similar, LightGBM was selected for its superior training speed, while XGBoost was slightly faster for live production predictions. They eventually standardized on LightGBM for most tree-based use cases due to its efficiency in their ML platform.
Source: DoorDash’s ML Platform: The Beginning – DoorDash Engineering
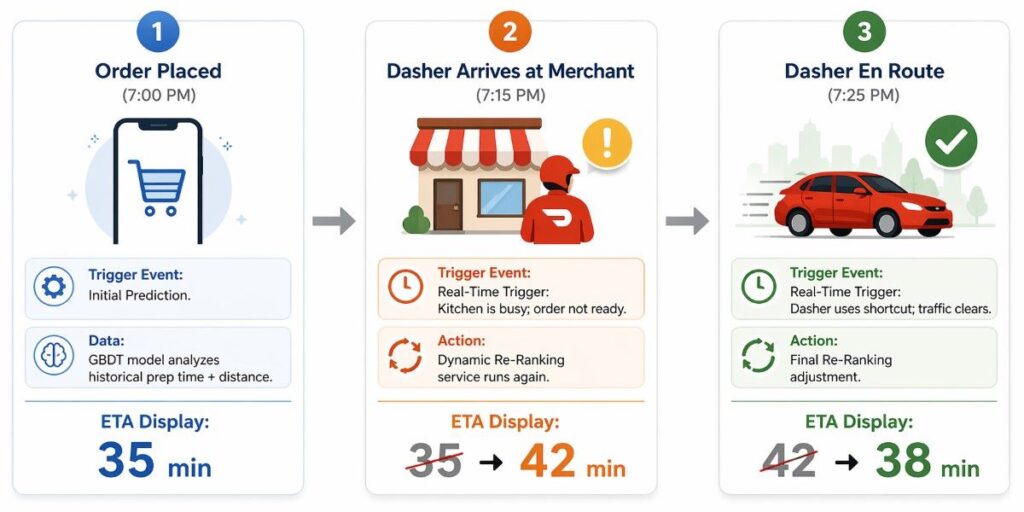
The Map that Moves: Dynamic Re-Ranking
The initial ETA you see when you click “Place Order” is not a static promise—it is a preliminary hypothesis. As your order moves through the physical world, DoorDash’s system continuously tests that hypothesis against a stream of real-time data. This process is known as Dynamic Re-Ranking.
Unlike traditional delivery services that might give you a single “30-minute” window and go silent, a modern ML system treats the delivery as a series of connected events. Each event provides a new “signal” that the model uses to re-calculate the final outcome.
Signal 1 (The Merchant): The kitchen confirms the order. If the “confirmation-to-ready” time starts dragging compared to the last ten orders at that restaurant, the system “re-ranks” the ETA upward in seconds.
Signal 2 (The Dasher): A Dasher is assigned. The model now switches from “Average Dasher Speed” to “Specific Dasher Profile.” Is this a top-tier veteran or a first-day rookie?
Signal 3 (The Journey): The Dasher hits a sudden traffic jam or a train crossing. The GPS pings feed into a streaming processor that realizes the previous route is no longer viable.
The Streaming Architecture
To make this work, DoorDash uses a Streaming ML Pipeline. This isn’t a model that waits for a database to update every hour; it is a system that “thinks” in motion.
The concept of moving from a single prediction to a dynamic, multi-stage update system is a cornerstone of DoorDash’s logistics philosophy. In their official documentation and patents, they describe this as a Successive Event Predictive Update System.
Closing the Loop: Feedback System
The brilliance of the DoorDash delivery time prediction ML is that it is a self-healing system.
Every completed delivery is a “Label” for the next training set.
If the model predicted 30 minutes and it took 45, that data point is instantly fed back into the Training Store.
By the next day, the model has “learned” that a specific intersection is closed for construction or that a specific restaurant has a new, slower cook on the Tuesday night shift.
Conclusion: More Than Just a Number
Predicting an ETA isn’t just about math; it’s about managing human expectations. DoorDash uses some of the world’s most sophisticated Geospatial ML and Gradient Boosting techniques to turn chaos into a predictable, 32-minute window.
The next time your app says “Arriving soon,” take a moment to appreciate the millions of “Hexagons,” “Decision Trees,” and “GPS Pings” working together to make sure your burrito arrives before your stomach starts singing to the whales again.
Was this helpful? If you’re building a logistics system or preparing for an ML interview, would you like to dive deeper into the specific Hyper-parameter Tuning DoorDash uses for their models? Comment below!





